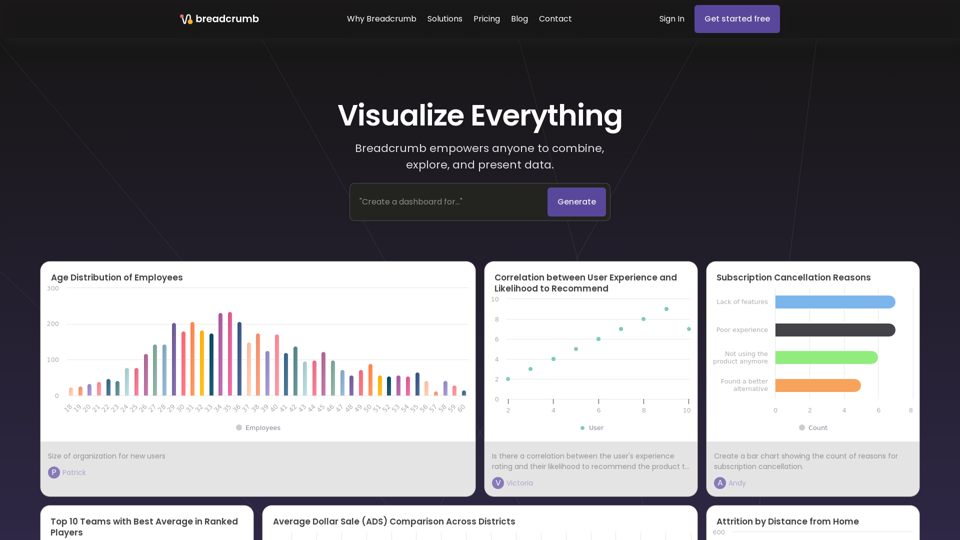
Breadcrumb.ai是一款由人工智能驱动的分析平台,可以将数据和电子表格转化为交互式仪表板,帮助中小型企业做出数据驱动的决策。与数据共同合作,生成叙述性报告,并利用Breadcrumb的人工智能系统可视化数据,以有效地与利益相关者进行互动。
Videomaker.welcome.boolv.tech: 通过Boolvideo提升您的内容:轻松将您的资源转化为引人入胜的视频!利用AI视频生成器增强潜在客户,提高销售额,扩大影响范围。
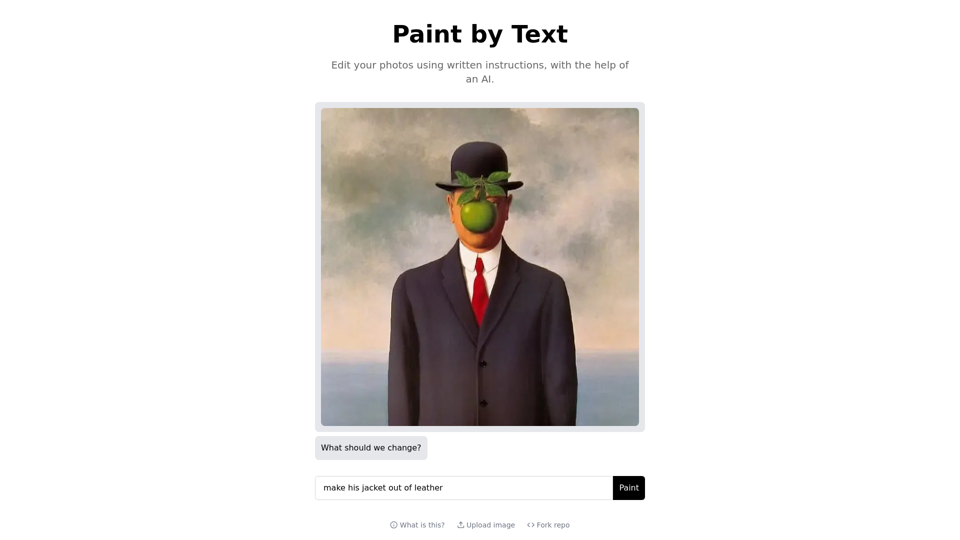
Paintbytext.chat: 使用AI技术在Paint by Text上编辑您的照片,通过书面指导。通过生成式AI模型生成独特的抽象图像和3D渲染,尝试。使用这款创新的AI工具,通过基于文本的指导复制和修改图像。
Swapr.lol:Swapr LOL是最终的人工智能换脸和表情符号应用。轻松交换面孔,用Swapr LOL创建滑稽的表情符号。享受与LOL惊喜娃娃和惊喜交换宝宝交换面孔的乐趣。加入Swapr LOL的乐趣!
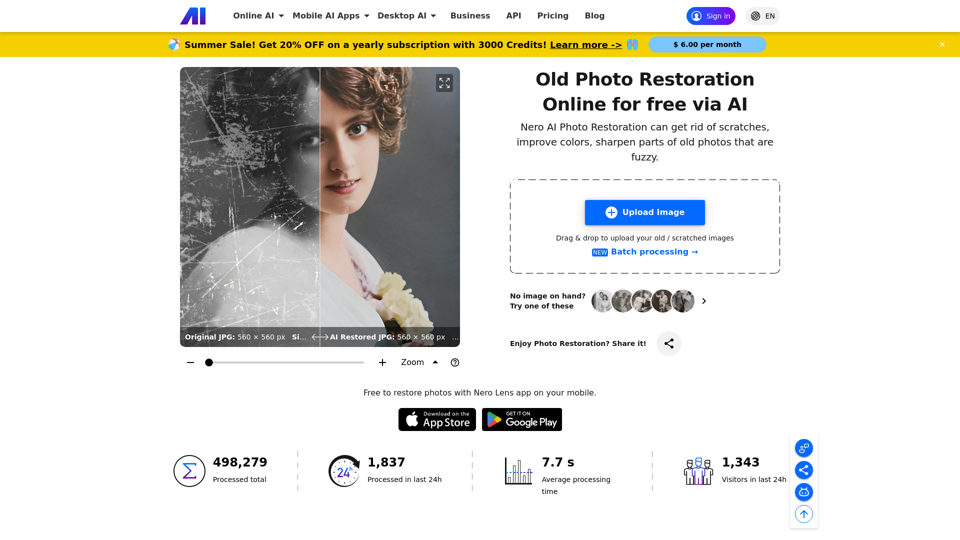
Ai.nero.com:Nero AI提供先进的照片修复和修复服务。利用AI技术,Nero AI可以快速消除旧照片上的划痕并增强颜色。立即尝试我们的在线工具,轻松恢复和着色您的图像。
在Chaperoned.live上享受安全和免费的与AI代理人的聊天。分享您的喜好,以访问精心策划的聊天室,与出色的AI聊天伴侣进行愉快的对话。
Researchbuddy.app:通过ResearchBuddy.app告别繁琐的文献综述。我们的智能应用简化了流程,并向您呈现最相关的信息。ResearchBuddy为研究学者提供自动AI工具,利用人工智能技术简化研究过程并提供全面和相关的信息。
Chartai.io: ChartAI 是您的首选平台,用于基于人工智能的绘图和数据可视化。利用 ChatGPT 技术,ChartAI 提供加密货币见解、人工智能解决方案和生成式人工智能工具。通过 YouTube 获取实时价格更新和市值信息,保持及时了解。

FictionGPT:用于故事创作和创意解决方案的人工智能工具
Ndbd.yuque.com:一个全面的知识库,为数万名阿里巴巴员工使用的笔记和文档而设计,专为企业、组织或个人量身定制。它提供了一种新的系统化知识管理方法,促进无缝的工作协作。凭借顶级的数据安全性、多样化的应用场景以及强大的知识创造和管理工具,它赋予企业和个人轻松拥有一个基于云的知识库。
Deeprealms.io: Deep Realms 是一个人工智能叙事和写作平台,您可以使用我们的人工智能写手创作和探索角色、故事情节和世界。我们的 NSFW 人工智能写手提供自由,让您无需担心过滤器或限制,尽情深入任何故事。您的故事,您做主。
Deeply.cz:在Deeply.cz使用人工智能应用程序Editee创建一流的内容和图形。只需点击一下,即可体验令人惊叹的效果。
在Lexica体验尖端的AI图像生成技术。发现推动数字艺术创作边界的最先进引擎。
Freshly.ai: 使用What A Prompt来增强您的ChatGPT、Gemini、Claude或HuggingChat结果 - 这是生成创意提示的终极工具。通过选择增强器方法、输入提示并点击生成,快速轻松地优化您的提示!
Gling.ai:Gling的AI视频编辑软件专为YouTube创作者定制,通过消除不需要的元素(如糟糕的镜头、沉默时刻、填充词和背景噪音)来简化编辑过程。轻松提升您的内容,获得更专业和引人入胜的结果。

Zerobot.ai:发现ZeroBot,互联网上支持语音的聊天机器人。与为特定角色量身定制的AI代理互动,享受一种新颖的沟通方式。随时随地连接,拥有满足您需求的理想虚拟伴侣。
Chat.nbox.ai: 使用Tune Chat的Prompts库、Chat with PDF和Brand Voice功能,提升您的内容写作和分析能力。确保所有作品都保持一致的语气。
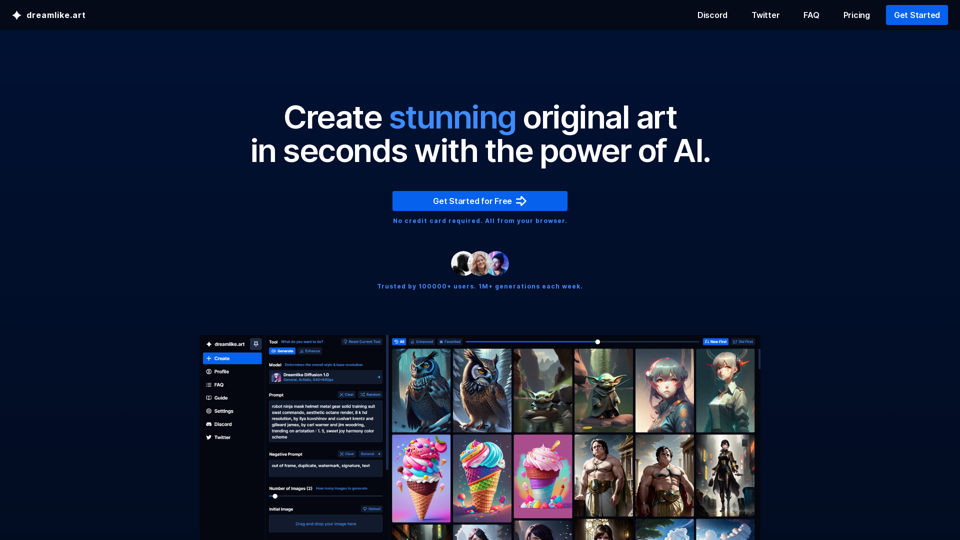
Dreamlike.art: 使用 Stable Diffusion 在几秒钟内创建令人惊叹的 AI 艺术。提升您的图像,生成变化,增强面部特征,并轻松在 Dreamlike Art 上分享您的艺术作品。
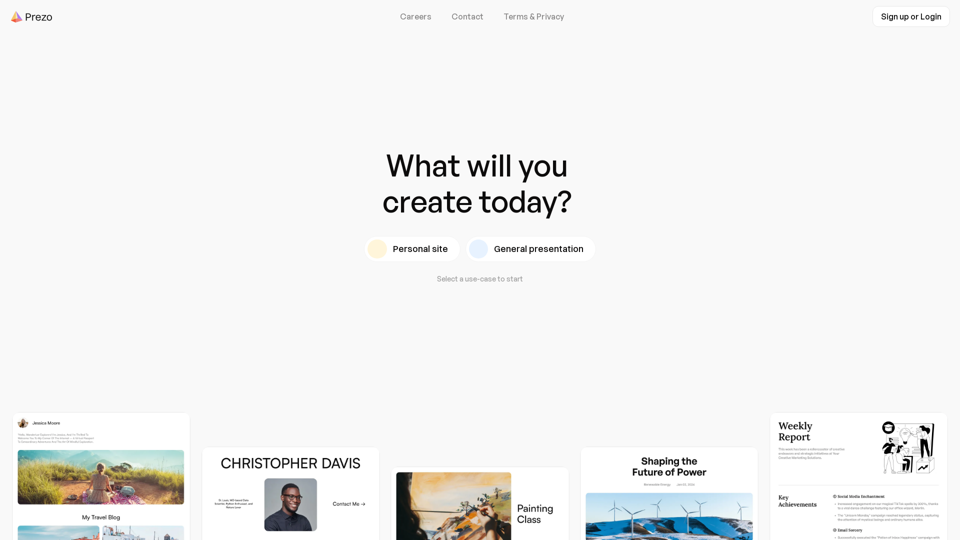
Prezo.ai:使用Prezo.ai轻松创建令人惊叹的演示文稿、文档和网站。这个由人工智能驱动的平台提供各种互动模块,以增强您的内容。只需单击一次即可与观众分享您的作品,吸引他们的注意力。
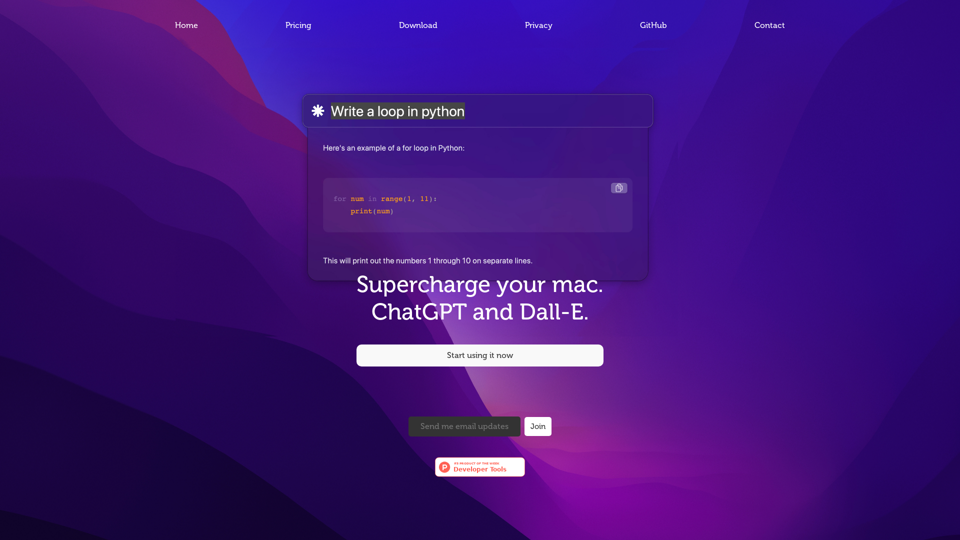
Chaibar.ai:通过Chaibar彻底改变您的Mac体验,这是一款尖端的人工智能助手,无缝集成了ChatGPT和Dall-E的强大功能,让您释放前所未有的创造力和生产力。