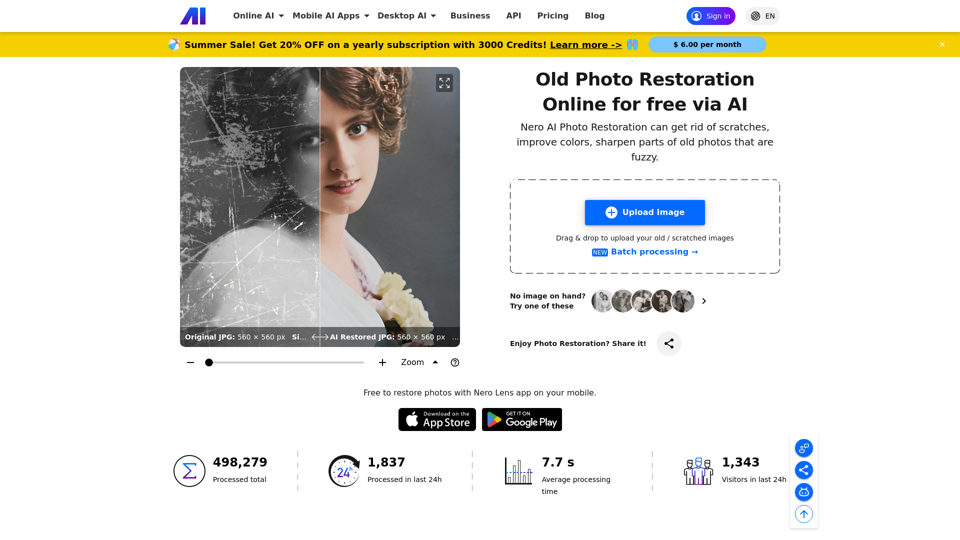


Qu'est-ce qu'un modèle de langage étendu (LLM) ?
Un modèle de langage étendu (LLM) est un type d'intelligence artificielle conçu pour comprendre et générer du texte de manière similaire à celle des humains. Ces modèles sont construits en utilisant des techniques d'apprentissage profond, en se concentrant particulièrement sur les réseaux neuronaux avec des architectures de transformateurs. Les LLMs sont entraînés sur de vastes ensembles de données pour apprendre les relations statistiques entre les mots et les phrases, ce qui leur permet d'effectuer une variété de tâches de traitement du langage naturel.
Caractéristiques clés des LLMs
- Architecture de transformateur : Utilise des mécanismes d'auto-attention pour un traitement efficace du texte.
- Pré-entraîné sur de grands ensembles de données : Ingère de vastes corpus de texte pour apprendre les motifs linguistiques.
- Capacités de réglage fin : Peut être ajusté pour des tâches spécifiques grâce à un entraînement supplémentaire.
- Capacités multimodales : Certains LLMs peuvent traiter et générer du texte, des images et d'autres types de données.
Avantages des modèles de langage étendu
Les LLMs offrent de nombreux avantages dans le domaine de l'intelligence artificielle et du traitement du langage naturel :
- Génération de texte améliorée : Capable de produire un texte cohérent et contextuellement pertinent.
- Compréhension du langage améliorée : Peut comprendre et inférer le sens à partir d'entrées linguistiques complexes.
- Applications polyvalentes : Utile dans divers domaines tels que la traduction, le résumé et l'analyse des sentiments.
- Évolutivité : Les modèles plus grands ont tendance à mieux performer sur une gamme plus large de tâches grâce à leurs données d'entraînement étendues.
Comment utiliser les modèles de langage étendu
L'utilisation des LLMs implique plusieurs étapes pour garantir leur intégration efficace dans les applications :
Déploiement
- Intégration API : De nombreux LLMs sont accessibles via des API, permettant une intégration facile dans les systèmes logiciels.
- Déploiement sur site : Certains modèles peuvent être déployés localement pour les applications nécessitant la confidentialité des données.
Réglage fin
- Entraînement spécifique à la tâche : Les LLMs peuvent être affinés avec des données supplémentaires pour améliorer les performances sur des tâches spécifiques.
- Conception de prompts : Élaboration de prompts spécifiques pour orienter les réponses du modèle dans les directions souhaitées.
Considérations
- Biais et éthique : Soyez conscient des biais potentiels dans les données d'entraînement et les résultats du modèle.
- Exigences en ressources : Les LLMs peuvent être gourmands en ressources, nécessitant une puissance de calcul significative pour l'entraînement et l'inférence.
- Surveillance continue : Évaluez régulièrement les performances du modèle et mettez-le à jour si nécessaire pour maintenir précision et pertinence.
En comprenant et en exploitant les capacités des modèles de langage étendu, les entreprises et les développeurs peuvent améliorer leurs applications avec des fonctionnalités avancées de traitement du langage.