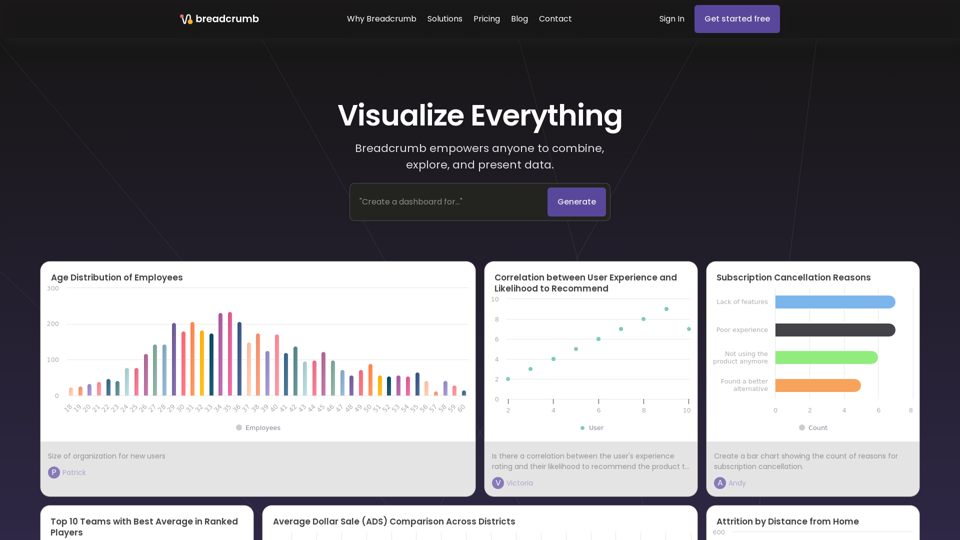
Breadcrumb.aiは、データとスプレッドシートをインタラクティブなダッシュボードに変換するAIパワードの分析プラットフォームです。中小企業がデータに基づいた意思決定を行うための支援を提供します。データと協力し、ナラティブレポートを生成し、ステークホルダーとの効果的な関与のためにBreadcrumbのAIシステムでデータを可視化します。
Videomaker.welcome.boolv.tech: Boolvideoでコンテンツを向上させましょう:リソースを効果的なビデオに変換して、簡単に魅力的なビデオに変えましょう!AIビデオジェネレーターを使用してリードを強化し、売上を増やし、リーチを拡大しましょう。
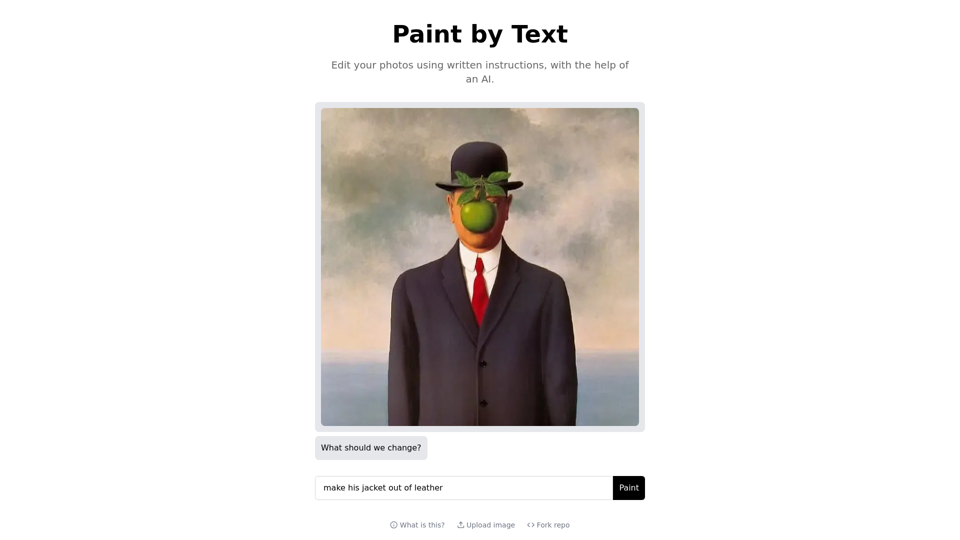
Paint by Textを使用して、AI技術を使って写真を編集しましょう。この革新的なAIツールを使って、テキストベースの指示で画像を複製および変更することができます。ユニークな抽象画像や生成AIモデルによって生成された3Dレンダリングを試してみてください。
Swapr LOLは究極のAIフェイススワップと絵文字アプリです。顔を簡単にスワップして、Swapr LOLで面白い絵文字を作成しましょう。LOLサプライズの人形やサプライズスワップトッツと一緒に顔を交換して楽しんでください。Swapr LOLで楽しい時間を過ごしましょう!
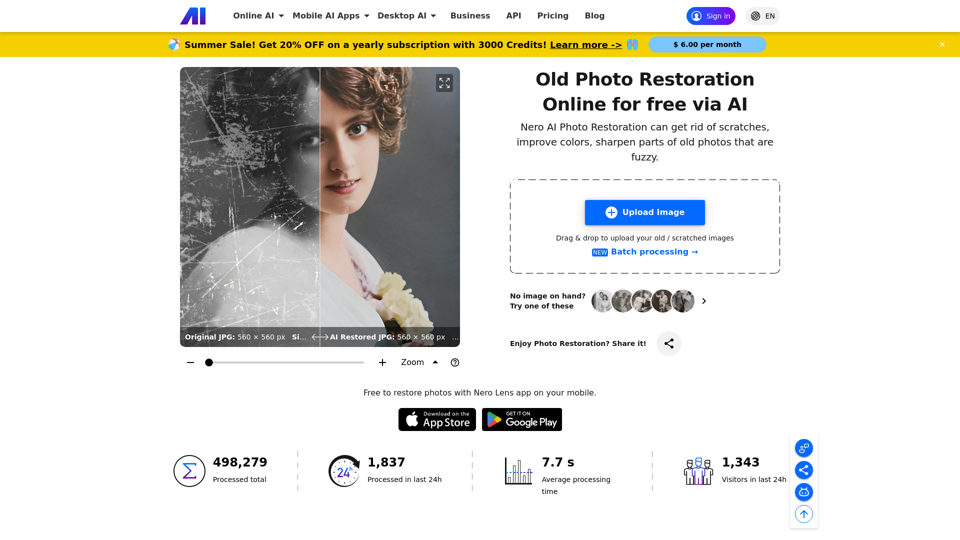
Ai.nero.com: Nero AIは、高度な写真修復および修理サービスを提供しています。AI技術を活用することで、Nero AIは古い写真の傷を素早く取り除き、色を強調することができます。今すぐオンラインツールをお試しください、手軽に画像を修復および着色化できます。
Chaperoned.live: Chaperoned.liveでAIエージェントと安全で無料のチャットを楽しんでください。好みを共有して、素晴らしいAIチャットコンパニオンとの楽しい会話を楽しむためにキュレーションされたチャットルームにアクセスしてください。
ResearchBuddy.app: 煩雑な文献レビューとはおさらば。ResearchBuddy.app は、スマートアプリを使ってプロセスを効率化し、最も関連性の高い情報を提供します。ResearchBuddy は、研究者向けの自動AIツールを提供し、AI技術を活用して研究プロセスを効率化し、包括的かつ関連性の高い情報を提供します。
ChartAIは、AIによる図式化とデータ可視化のためのプラットフォームです。ChatGPTテクノロジーを活用して、ChartAIは暗号通貨の洞察、人工知能ソリューション、および生成AIツールを提供します。YouTubeでライブの価格更新と時価総額情報を確認してください。

FictionGPT: ストーリー執筆や創造的な解決策のためのAIツール
Ndbd.yuque.com: アリババの数万人のスタッフが使用するノートや文書の包括的な知識ベースで、ビジネス、組織、個人向けにカスタマイズされています。知識管理に新しい体系的なアプローチを提供し、シームレスな作業協力を促進します。トップティアのデータセキュリティ、多様なアプリケーションシナリオ、堅牢な知識創造および管理ツールを備え、企業や個人が雲ベースの知識リポジトリを簡単に所有できるよう支援します。
Deeprealms.io: Deep Realmsは、AIストーリーテリングおよびライティングプラットフォームであり、AIライターと共にキャラクターや物語、世界を作成し探索できます。NSFW AIライターは、フィルターや制限なしにどんな物語にも没入する自由を提供します。あなたの物語、あなたのルール。
Deeply.czで、人工知能アプリケーションEditeeを使用して、最高品質のコンテンツとグラフィックを作成してください。たった1クリックで息をのむような結果を体験できます。
Lexicaで最先端のAI画像生成技術を体験してください。デジタルアート創造の限界を押し広げる最新エンジンを発見してください。
Freshly.ai: ChatGPT、Gemini、Claude、またはHuggingChatの結果をWhat A Promptで強化し、創造的なプロンプトを生成する究極のツール。強化方法を選択し、プロンプトを入力して生成ボタンをクリックすることで、簡単かつ迅速にプロンプトを最適化できます!
Gling.ai: GlingのAIビデオ編集ソフトウェアは、YouTubeクリエイター向けに設計されており、悪いテイク、無音の瞬間、フィラーワード、背景ノイズなどの不要な要素を排除することで編集プロセスを効率化します。よりプロフェッショナルで魅力的な結果を簡単に向上させてください。

Zerobot.ai: ZeroBotを見つけて、インターネットの音声対応チャットボットを体験しましょう。特定の役割に合わせたAIエージェントとやり取りし、革新的なコミュニケーション方法を楽しみましょう。いつでもどこでも、あなたの要件に最適な仮想コンパニオンとつながりましょう。
Chat.nbox.ai: Tune ChatのPromptsライブラリ、Chat with PDF、およびBrand Voice機能でコンテンツ執筆と分析を向上させます。すべての作成物で一貫したトーンを確保します。
Dreamlike.art: 安定拡散を使用して数秒で見事なAIアートを作成します。 画像を拡大し、バリエーションを生成し、顔を強調し、Dreamlike Artで簡単にアートを共有します。
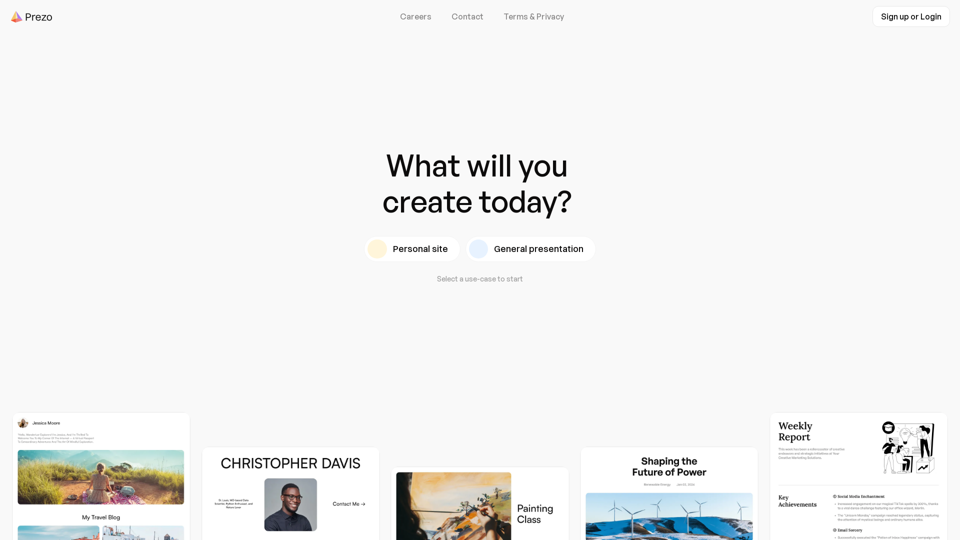
Prezo.ai: Prezo.aiを使って、驚くほど素晴らしいプレゼンテーション、文書、ウェブサイトを簡単に作成できます。このAI搭載プラットフォームは、幅広いインタラクティブブロックを提供し、コンテンツを強化します。作成物を1クリックで共有し、観客を魅了しましょう。
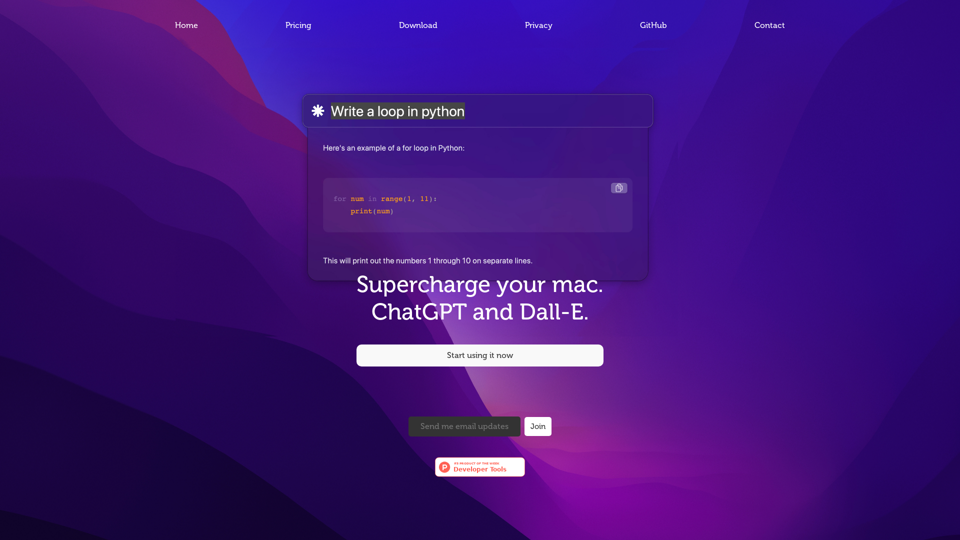
Chaibar.ai: Chaibarを使用してMacの体験を革新しましょう。この先端のAIアシスタントは、ChatGPTとDall-Eのパワーをシームレスに統合し、前例のない創造性と生産性を引き出すことができます。