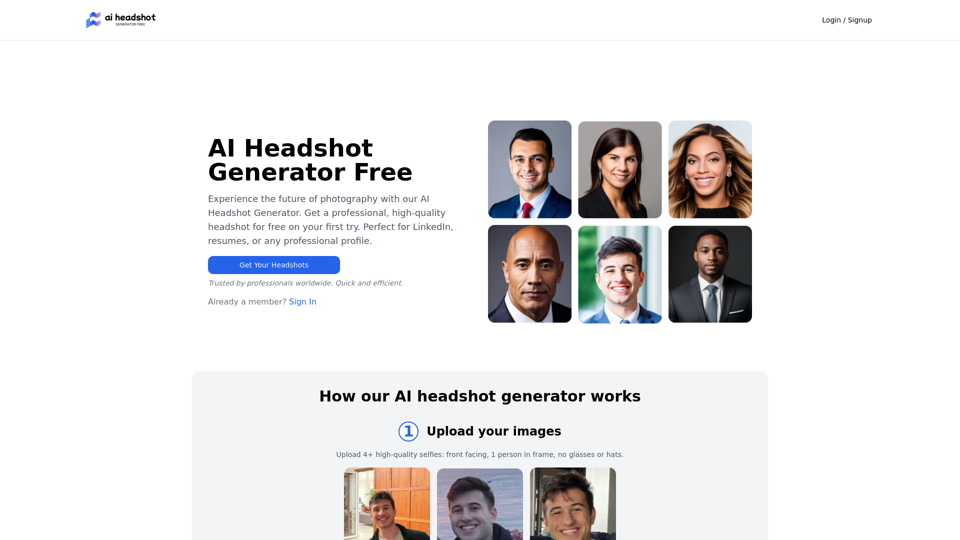

什麼是 AI 圖像識別?
AI 圖像識別是一種技術,使機器能夠識別和分類圖像中的物體,模仿人類級別的視覺理解。它利用先進的人工智慧,特別是深度學習,來處理和解釋視覺數據,將物體分類為不同的類別。這項技術是計算機視覺的一個子集,在從面部識別到醫學成像的各種應用中具有關鍵作用。
AI 圖像識別的好處
AI 圖像識別在不同行業中提供了許多優勢:
- 醫療保健: 增強醫學影像分析,協助診斷和治療計劃。
- 零售業: 促進庫存管理和顧客行為分析。
- 安全: 通過檢測和跟踪物體或可疑活動來改善監控系統。
- 農業: 協助監控作物健康和管理牲畜。
- 汽車: 對自動駕駛車輛至關重要,用於檢測周圍物體和路標。
如何使用 AI 圖像識別
實施 AI 圖像識別模型
-
數據收集和標註:
- 收集大量的圖像數據集。
- 用有意義的標籤或標記對圖像進行標註以供訓練。
-
訓練神經網絡:
- 使用卷積神經網絡(CNN)訓練標註的數據集。
- CNN 自動從圖像中學習重要特徵以進行準確識別。
-
模型測試和部署:
- 使用新的圖像測試訓練好的模型以評估性能。
- 部署模型以進行實時圖像識別任務。
流行算法
- 卷積神經網絡(CNN): 利用多層結構從圖像中提取特徵。
- You Only Look Once(YOLO): 在單次處理中完成圖像的快速物體檢測。
- Single Shot Detector(SSD): 將圖像劃分為網格以提高物體檢測效率。
在各個領域的應用
- 面部分析: 檢測和分析面部特徵以進行身份驗證和情感識別。
- 醫學成像: 協助分析 CT 掃描、MRI 和 X 光片以檢測疾病。
- 安全系統: 通過實時識別潛在威脅來增強監控能力。
AI 圖像識別繼續通過提供高效且準確的視覺數據處理來革新各行業,使其成為現代技術領域中不可或缺的工具。