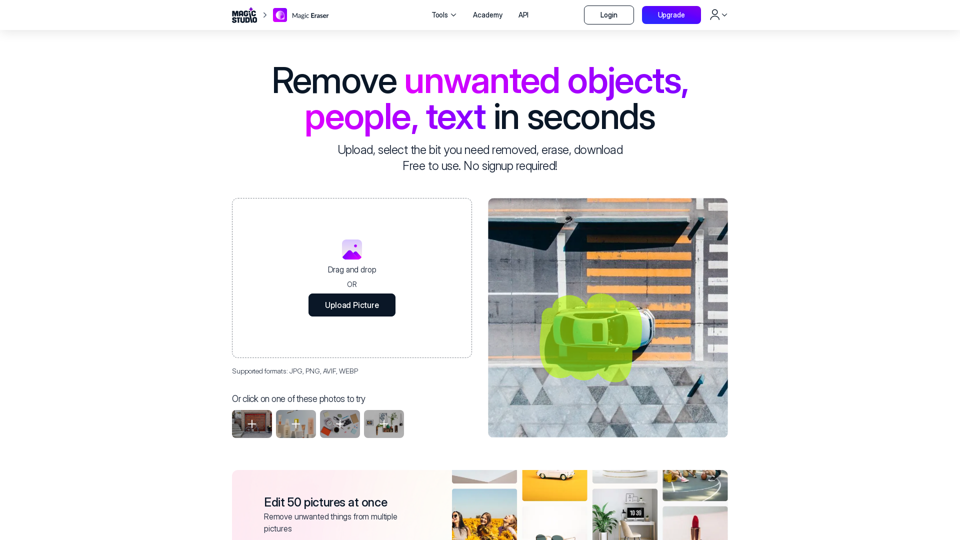
Magicstudio.com:使用Magic Eraser輕鬆在幾秒鐘內從照片中刪除物體、人物、文字、瑕疵和圖案。這款由人工智慧驅動的工具可讓您精確選擇並擦除,提供無限免費使用,無需註冊。
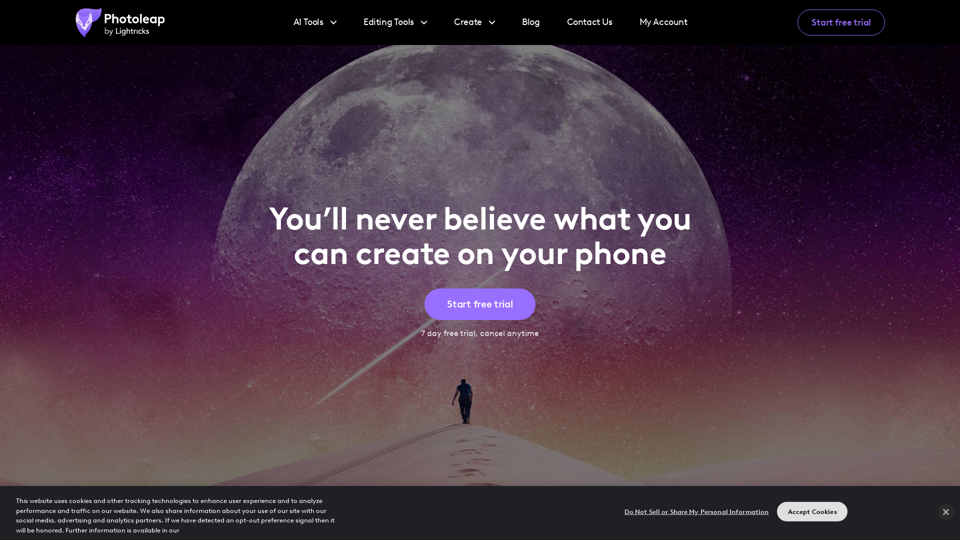
Photoleapapp.com: 使用 Photoleap,這款全能照片編輯器,讓您改變 iPhone 照片,創造令人驚豔的作品。更換背景、移除物件、製作拼貼,應用濾鏡和特效。立即開始您的 7 天免費試用!
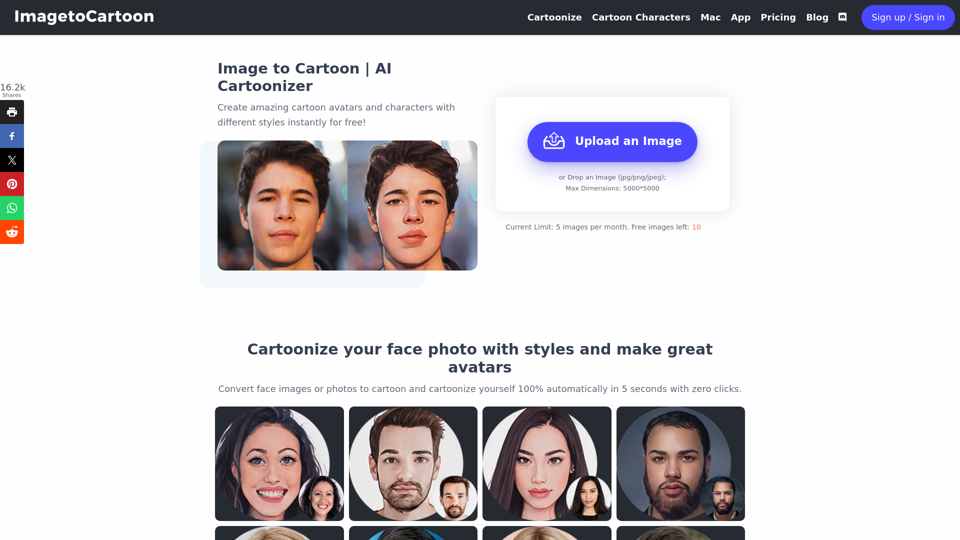
Imagetocartoon.com:使用我們先進的2D和3D卡通角色創建器,將您的圖像變成驚人的卡通頭像。讓您的創造力發揮,將您的想法變為現實!
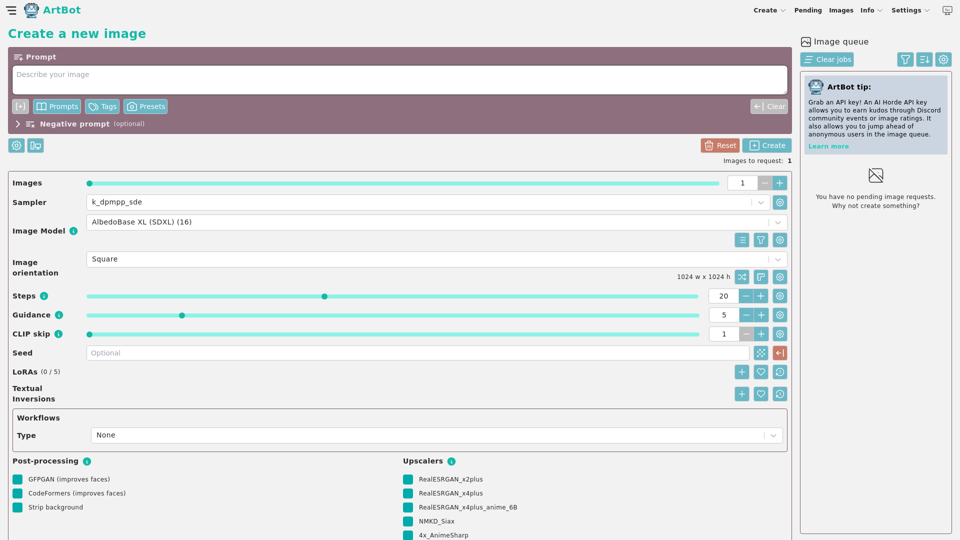
Tinybots.net:在Tinybots Artbot上使用Stable Diffusion創建由AI生成的圖像和照片。利用由AI Horde提供動力的分佈式計算集群進行無縫圖像生成。無需登錄,完全免費使用。
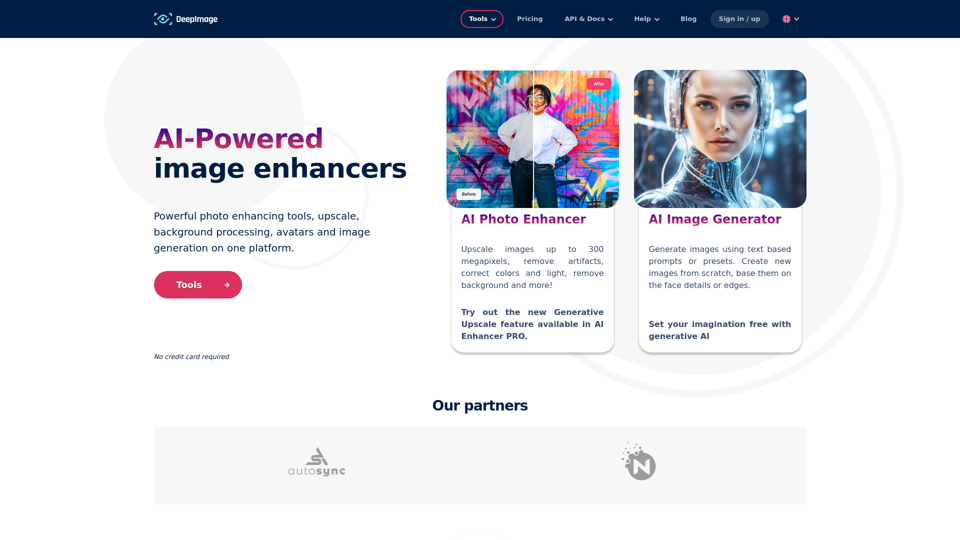
Deep-image.ai: 通過Deep Image AI輕鬆增強圖像、創建AI頭像並轉換背景。無需信用卡,免費試用我們的服務。提升您的電子商務視覺效果,重新想像房地產攝影。
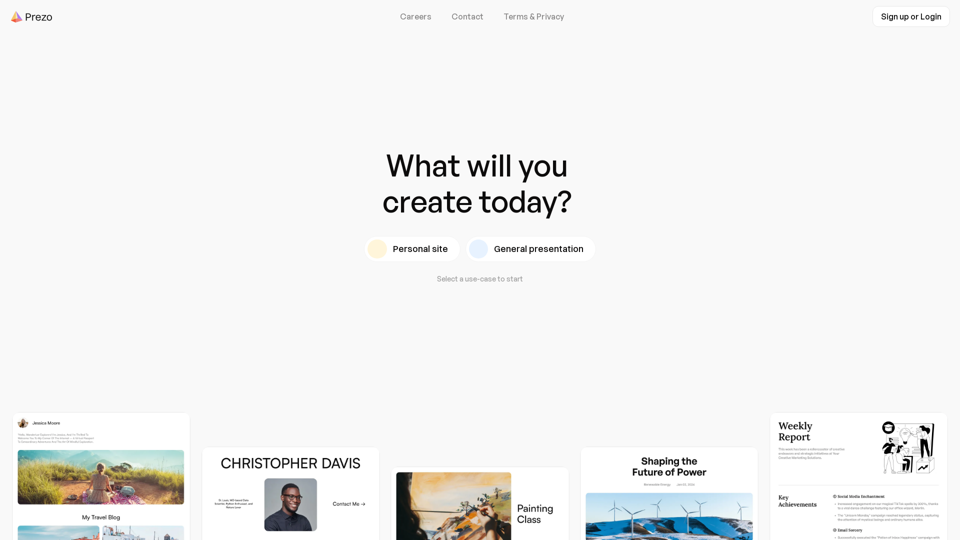
Prezo.ai:使用Prezo.ai輕鬆創建令人驚艷的演示文稿、文件和網站。這個由人工智慧驅動的平台提供各種互動塊,以增強您的內容。只需點擊一下即可分享您的創作,吸引您的觀眾。
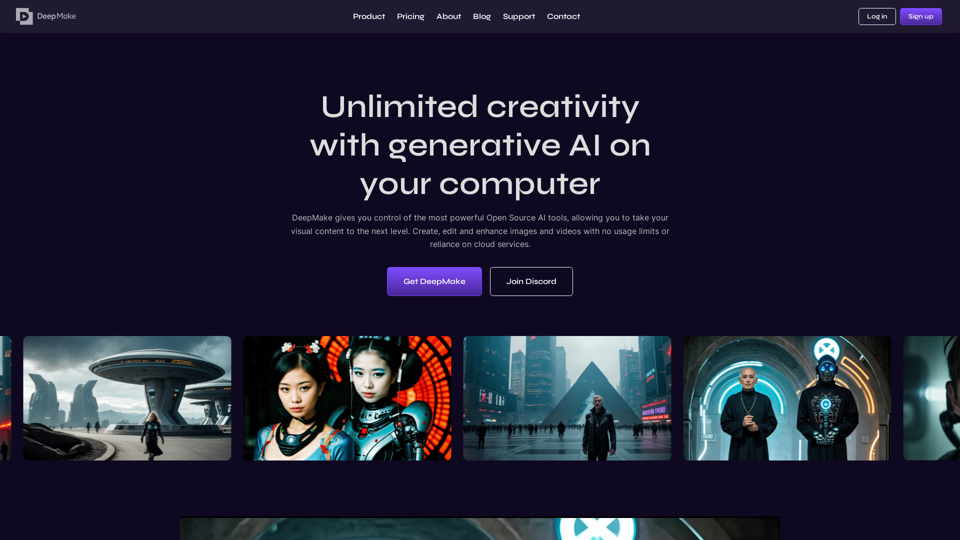
Deepmake.com:DeepMake利用生成式人工智慧輕鬆快速地優化內容創作。利用尖端的開源人工智慧技術,我們提供僅需點擊幾下即可獲得VFX,從文字提示生成庫存影片,即時分割圖層,並提供一系列其他創新解決方案。

Fantoons.xyz:通過AI生成的粉絲漫畫,探索哈利波特和BTS的神奇世界,無需藝術技能,在Fantoons上,幻想與技術相遇,創意無限。
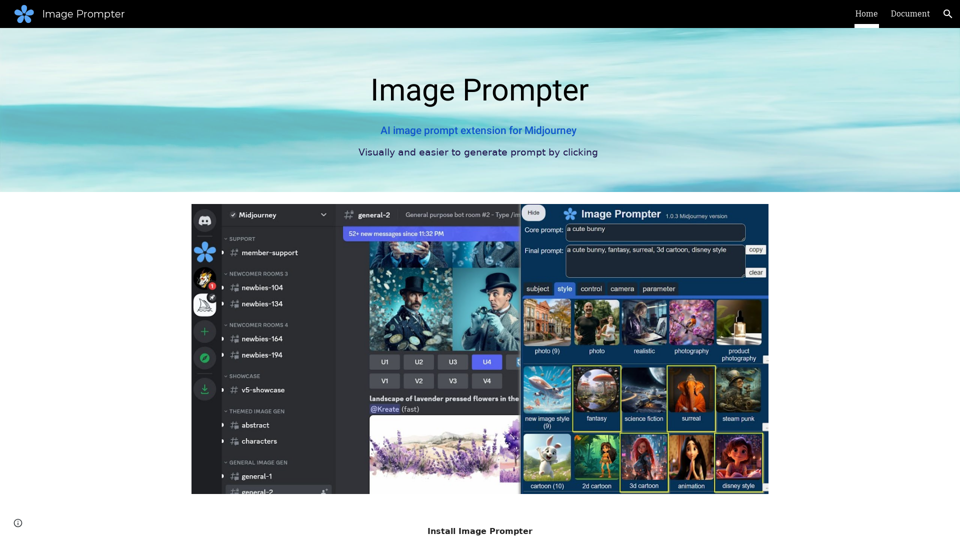
透過 Image Prompter,一款革新設計工作流程的尖端工具,來提升您的設計效率,改變您創建和完善視覺內容的方式。
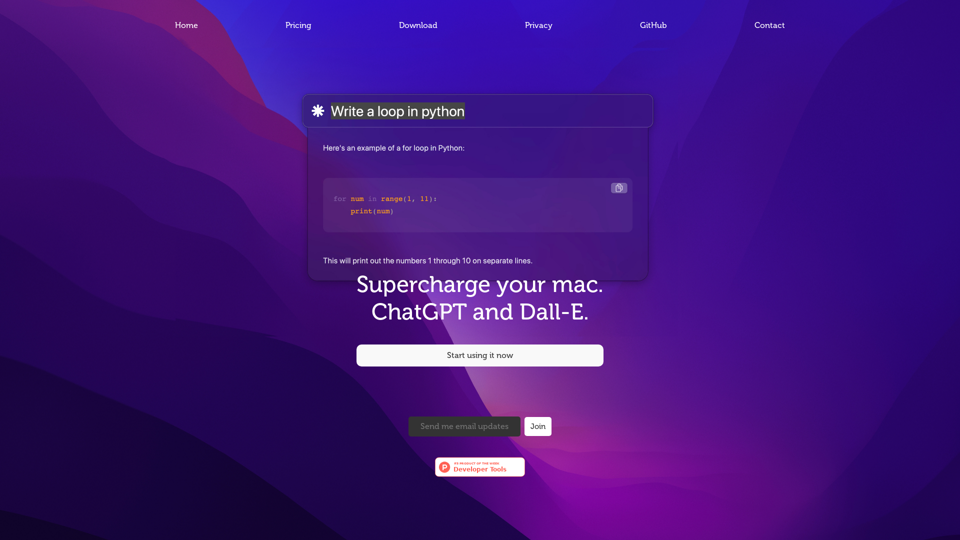
Chaibar.ai: 透過 Chaibar 來改變您的 Mac 體驗,這是一款尖端的 AI 助理,無縫集成了 ChatGPT 和 Dall-E 的功能,讓您能夠開啟前所未有的創造力和生產力。
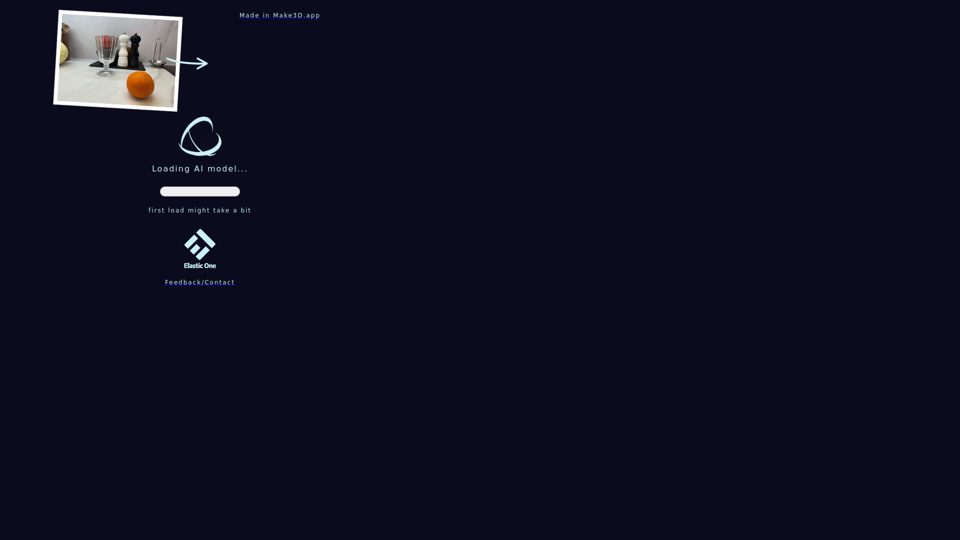
Make3d.app:使用Make3D將您的圖像轉換為3D,這是一個強大的在線工具,可以將您的照片變成令人驚嘆的三維作品。
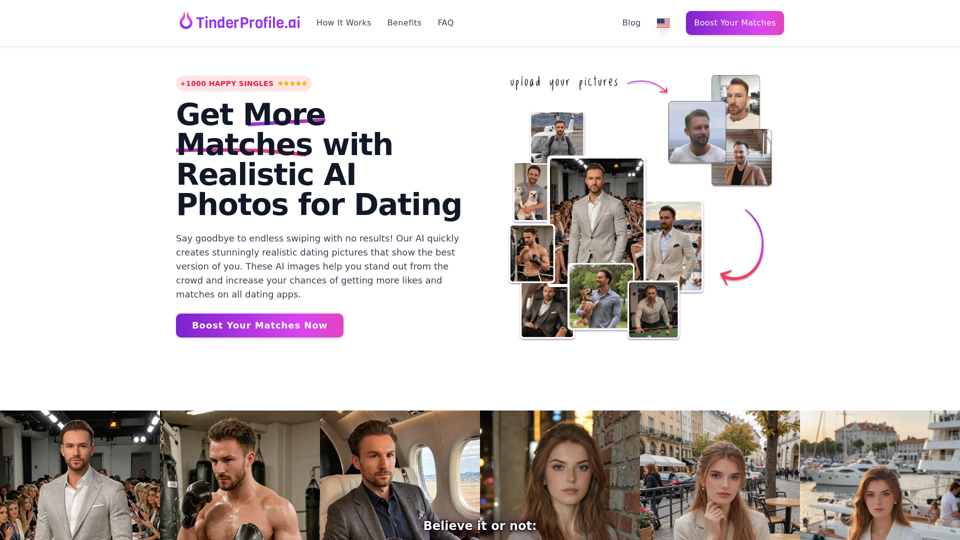
Tinderprofile.ai: 使用人工智慧提升您的Tinder配對,進行個人資料優化 | TinderProfile.ai
Stability.ai:Stability.ai 的 Stable Diffusion XL 和 SDXL Turbo 通過更短的提示來改變圖像生成,創造出具有增強組成和真實美感的描述性圖像,開啟無與倫比的創意可能性。
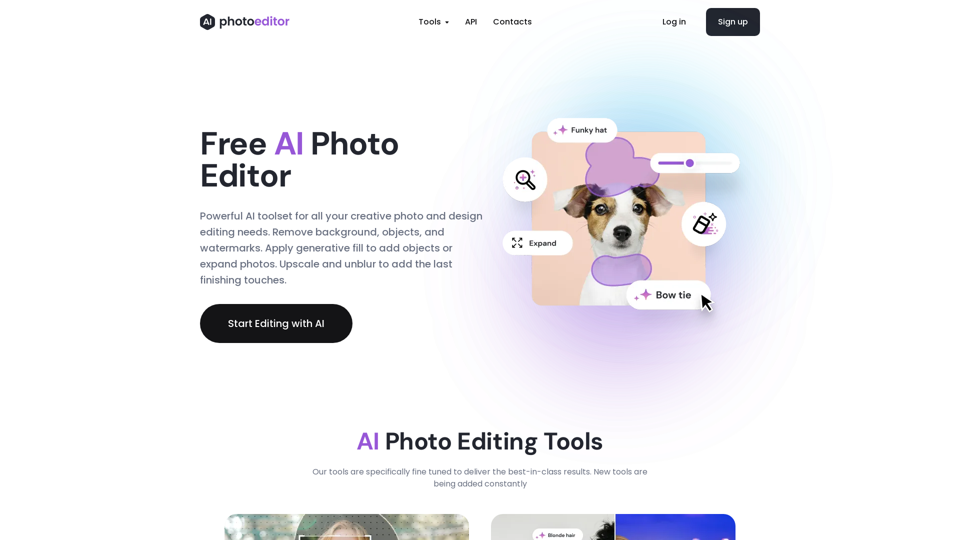
Photoeditor.ai:AI 助力的照片編輯工具,可立即增強圖像,免費在線移除不需要的物件、人物、文字或浮水印,並體驗無縫編輯的尖端技術。
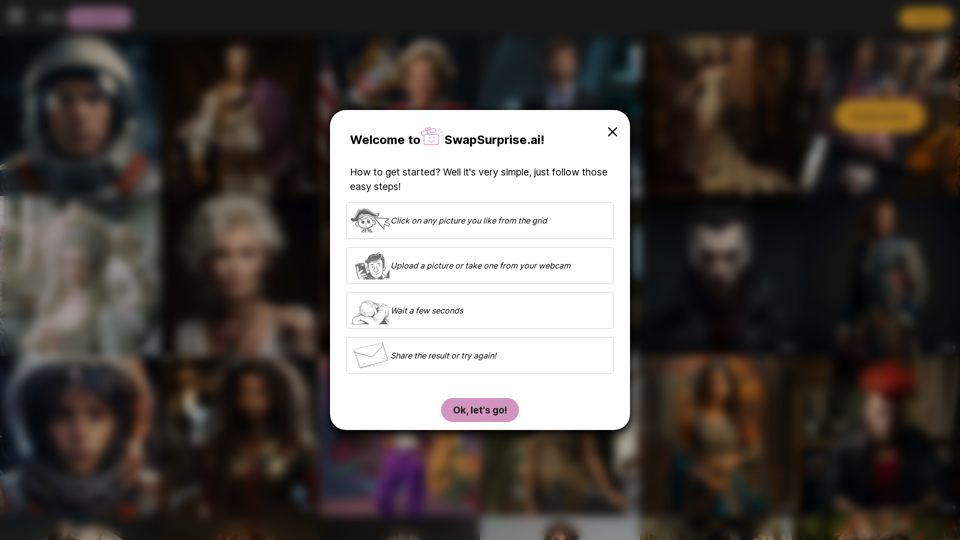
Swapsurprise.ai:體驗AI動力人臉交換的魔力,Swapsurprise將尖端技術與創意相結合,讓您可以在幾秒鐘內將您的臉交換到令人驚嘆、有趣和藝術的圖像中。
Newtype.ai:使用NewtypeAI直观的基于Web的界面轻松创建令人惊叹的AI角色图像,只需点击几下即可让您喜爱的角色栩栩如生,提供无与伦比的便利性和稳定性。
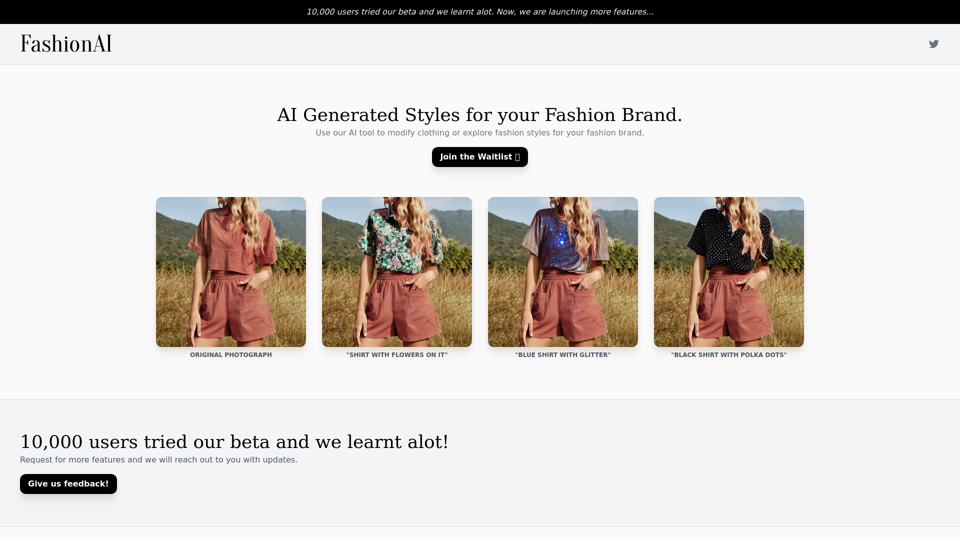
Fashionai.me:在FashionAI體驗由人工智慧驅動的時尚探索,一張人的照片可以被轉換成虛擬時尚達人,讓用戶試穿不同的服裝風格並發現最新的時尚趨勢。
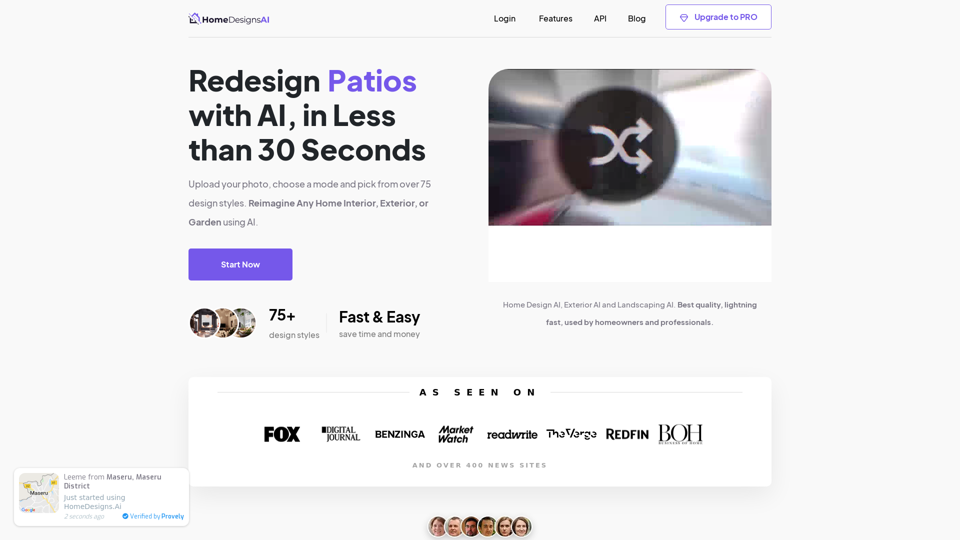
Homedesigns.ai:透過 AI 技術生成的室內、室外和花園設計,讓您在不到 30 秒內探索家居設計的未來,Homedesigns.ai 正革新您打造夢想家園的方式。
FlowGPT 是 ChatGPT 的視覺界面,具有多線程視覺對話流
OLMO - 軟體、應用程式、SaaS 和新創企業專案登陸頁套件